Системы с высокой доступностью
Серия статей, цель которых осветить вопросы проектирования и эксплуатации информационных систем и сервисов с требуемым для организации уровнем надежности. Введение в проблематику, освещаются ключевые концепции, связанность с другими вопросами ведения деятельности организации. Статьи предназначены преимущественно для руководителей проектов, собственников продуктов, а также для технических специалистов занятых в проектировании и организации работ.
Данная статья является первой в серии, примерный состав серии:
-
Системы с высокой доступностью и аварийное восстановление. Введение. (эта статья)
-
Системы с высокой доступностью и аварийное восстановление. Сбои: причины и классификация.
-
Высокая доступность: концепции, общие практики построения и сопровождения.
-
Аварийное восстановление: основы
-
Аварийное восстановление: восстановление после сбоя
-
Архитектура высокодоступных систем: основы
-
Архитектура высокодоступных систем: базовые требования и сценарии отказа обслуживания
-
Архитектура высокодоступных систем: расчет надежности
С вопросами проектирования и эксплуатации информационных систем сейчас сталкиваются практически в любой отрасли и сфере деятельности человечества где есть потребность в автоматизации и информационной поддержки. Довольно часто, эта автоматизация или информационная поддержка могут сами быть критически важными элементами процессов, обеспечивающих функционирование организации, например быть неотъемлемой частью основного бизнес-процесса или же сами являться продаваемой услугой. Так как от них начинает зависеть сама реализация деятельности или непосредственное получение дохода, то практически сразу же возникает и вопрос их надежности и согласованности с ограничениями и условиями ведения этой самой деятельности.
Связь с другими областями (business continuity)
Данная тема практически всегда рассматривается как часть другой большой темы - обеспечение непрерывности ведения бизнеса/деятельности (business continuity), которая отвечает за меры по обеспечению доступа к ресурсам для критически важных для организации активностей. К сожалению далеко не все организации руководствуются какими бы то ни было стандартами (региональными, отраслевыми, даже собственными), регламентами или соглашениями. Но при достижении определенного масштаба или увеличения важности информационной системы становится понятно, что дешевле предотвратить инцидент или как-то его обработать, чем столкнуться с его последствиями без заранее предпринятых для его ликвидации мер. Довольно очевидно, что в таких случаях исходят из потребностей организации, а уже на основе них формируются и требования к обеспечению непрерывности функционирования организации через защитные меры.
Почему это нужно для бизнеса
Как правило в обеспечении надежности эксплуатируемой организацией системы стоит начинать с потребностей самой организации. Для этого нужно структурировать ее цели и потери которые могут вызвать отказы системы, их масштабы и показатели. Обычно цели организации определяются через уже установленные стандарты business continuity и через управление рисками, но эта тема вне серии статей. Клаус Шмидт в книге “High availability and disaster recovery. Concepts, design, implementation” предлагает следующую классификацию для описания ущерба организации в случае отказа:
-
Прямые затраты - затраты на ремонт, закупку нового оборудования, восстановление работоспособности
-
Дополнительное рабочее времени - непрямые затраты связанные с обработкой любого инцидента специалистами
-
Потерянное эффективное рабочее время - также непрямые затраты, связанные с невозможностью выполнения бизнес-задач персоналом, работу которых затронул отказ.
-
Потерянная выручка - невозможность обработать транзакции (любого вида) от экономического агента.
Известные |
Оценочные |
|
Выручка |
Потеря выручки |
Потерянное эффективное рабочее время |
Затраты |
Прямые затраты |
Дополнительное рабочее время |
Наиболее очевидная цена сбоя и простоя системы и вероятно наиболее затратная - уменьшение пользовательской продуктивности. Фактическая цена простоя зависит от того на какую пользовательскую деятельность сбой повлиял и какое количество пользователей он затронул. Простой пример:
-
Во внутренней инфраструктуре фирме, предоставляющей некоторый онлайн-сервис произошел сбой, в результате которого сотрудники потеряли возможность работать с тестовыми контурами (test environment) в течении двух дней.
-
Пользователи разработчики и тестировщики со средней ставкой в $60 за час, сбой в инфраструктуре привел к невозможности работы для 30 человек.
-
Восстановление работоспособности силами двух администраторов привел к тратам на 16 сверхурочных рабочих часов по той же ставке.
-
Разработчики работали над исправлением ряда дефектов и тремя новыми функциями для сервиса, выпуск новой версии сдвинулся на три дня. Согласно расчетам вывод новых функций должен приносить дополнительно по $21000 выручки в день. Более того, один из дефектов сильно затрудняет работу сотрудников клиента, чем он недоволен и руководителю организации или менеджеру продукта приходится тратить дополнительные усилия на то, чтобы дополнительно проинформировать клиента, возможно предпринять какие-то еще действия, чтобы тот в целом был удовлетворен оказываемым сервисом и продолжал поддерживать или даже увеличивать выручку организации.
И так имеем следующий список затрат. Простой в работе для разработчиков и тестировщиков:
$50 * 8 часов * 2 дня * 30 человек = $24000
Сверхурочные для администраторов:
$50 * 16 часа * 2(коэффициент за сверхурочные) = $1600
Недополученная выручка:
$21000 * 3 дня = $63000
Пример крайне поверхностный и окончательный подсчет ущерба от сбоя зависит от правил учета затрат в организации и текущих планов по выручке. Если план включал не только те три разрабатываемые фичи, тогда имеет смысл использовать cost of delay показатель и для более отдаленных релизов. Но не стоит все затраты, понесенные во время сбоя, списывать на его ликвидацию.
Кроме выше изложенных потерь к последствиям сбоя можно отнести:
-
Уменьшение удовлетворения клиентов;
-
Уменьшение морали сотрудников;
-
Репутационные потери;
-
Падение стоимости акций компании (если такие имеются);
-
Юридическая ответственность в случае несоответствия заявленным стандартам или договорам.
На основе известных понесенных или потенциальных потерь выручки и затрат на восстановление работоспособности уже можно планировать меры по минимизации ущерба. При наличии информации о стоимости фактического простоя, подобные меры обосновываются для владельцев крайне просто (с фактами не спорят), а интересы сторон уже известны.
Математика доступности
И так, в принципе очевидно - простой стоит денег, причем немалых. И чем большее число пользователей было затронуто отказом и чем значительнее затронутые бизнес-процессы, тем дороже этот самый простой обходится. Нет смысла абсолютно точно считать понесенные убытки, чтобы убедиться в их больших размера, пример:
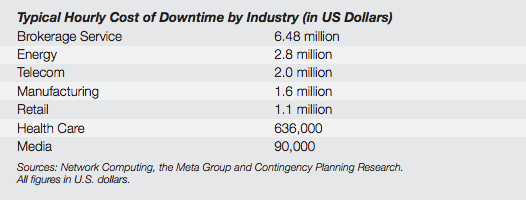
Собственно формула расчет доступности:
A = MTBF / (MTBF + MTTR)
A - собственно сам показательно доступности
MTBF - mean time between failures (среднее время между отказами)
MTTR - maximum time to resolve (максимальное время восстановления)
Для удобства A умножают на 100, чтобы получить процент бесперебойной работы, именно из этого показателя формируется всем известная “доступность” по количеству девяток. На всякий случай таблица с ними для 24х7 сервисов:
% бесперебойной работы |
% недоступности |
Время простоя в год |
Время простоя в неделю |
98% |
2% |
7.3 дня |
3 ч. 22 мин. |
99% |
1% |
3.65 дня |
1 ч. 41. мин |
99.9% |
0.1% |
8 ч. и 45 мин |
10 мин. 5 сек |
99.99% |
0.01% |
52.5 мин |
1 мин. |
При эксплуатации системы и расчете доступности не всегда имеется в виду, что система эксплуатируется круглосуточно и весь год. Поэтому если кто-то декларирует доступность в несколько девяток следует уточнить в каких временных интервалах и как декларируют графики обслуживания системы для клиентов. Обычно в секции Service Level Agreement (SLA) оговаривается время когда именно эта сама доступность измеряется. Чаще всего используют привычные многим обозначения с HxD, где H - количество рабочих часов в сутках, D - количество рабочих суток в неделе.
Типичные варианты:
-
24 x 7 - круглосуточно, опционально прописываются часы обслуживания (maintenance window)
-
24 x 6 - 6 выбранных дней в неделю
-
14 x 5 - рабочие часы в будний день
Теперь сводная таблица:
SLA (%) |
24x7 |
24x6 |
14x5 |
|||
Месяц |
Год |
Месяц |
Год |
Месяц |
Год |
|
99 |
7.3ч |
3.7д |
6.3ч |
3.1д |
3.0ч |
1.5д |
99.5 |
3.7ч |
1.8д |
3.1ч |
1.6д |
1.5ч |
18.3ч |
99.8 |
1.5ч |
17.5ч |
1.3ч |
15.0ч |
36.6мин |
7.3ч |
99.9 |
43.8мин |
8.8ч |
37.6мин |
7.5ч |
18.3мин |
3.7ч |
99.99 |
4.4мин |
52.6ч |
3.8мин |
45.1мин |
1.8мин |
21.9мин |
99.999 |
26.3сек |
5.3мин |
22.6сек |
4.5мин |
11.0сек |
2.2мин |
При таком подходе в оценке доступности системы необходимо отметить следующее:
-
Относительно чего была замерена доступность, если доступ осуществляется через один из нестабильных маршрутов, то относительно его пользователей доступность будет ниже
-
Выше приведенные “девятки” есть среднее значение, гораздо важнее видеть MTTR, хотя по маркетинговым соображениям его иногда и не публикуют.
-
Иногда публикуют теоретические данные, основываясь на построенной модели, но важно вести замер фактической доступности и не забывать при этом про п1.
При обсуждении SLA имеет смысл обсуждать и фиксировать в договоренностях не абстрактные девятки процента доступности сервисов, а фактические (то есть абсолютные) показатели доступности сервисов в рабочие часы, чтобы избежать недопониманий и ложных ожиданий в будущем. Также не стоит недооценивать трудности достижения показателей высокой доступности таких как 99.99%, 53 минуты простоя в год должны означать, что организация имеет возможность обработать даже самый катастрофический сбой в системе менее чем за 1 час.
В следующей статье (Системы с высокой доступностью и аварийное восстановление. Вынужденные простои и сбои: причины, классификация, затраты.) будут рассмотрены основные причины сбоев, различные их классификаторы, ключевые этапы преодоления сбоя, его оценка.
Alexander Salimonov
Engineering Manager
Distributed and data-intensive sytems, databases, data processing, cloud computing.